We are going to start off this semester of code club with a series of sessions on how to “wrangle” your data. It can be a struggle to get data into a format that is amenable for analysis, so we will be going through a series of functions and approaches that will get you more comfortable with manipulating your data.
“Yet far too much handcrafted work — what data scientists call “data wrangling,” “data munging” and “data janitor work” — is still required. Data scientists, according to interviews and expert estimates, spend from 50 percent to 80 percent of their time mired in this more mundane labor of collecting and preparing unruly digital data, before it can be explored for useful nuggets.” - For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights, NY Times
If you don’t have R and RStudio on your computer, you can find instructions for installation here. You can also find some additional introductory material on getting set up in RStudio here.
1.0.1 Poll - who is new to R?
1.1 Load libraries
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
1.2 Data
We are going to use data from The World Factbook, put together by the CIA to “provides basic intelligence on the history, people, government, economy, energy, geography, environment, communications, transportation, military, terrorism, and transnational issues for 265 world entities.” I thought this data would give us some opportunities to flex our R skills, and learn a bit about the world.
The data we are going to download can be found here, though I have saved the file, added it to our Code Club Github, and included some code below for you to download it.
Rows: 217 Columns: 53
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): Country Name, Country Code
dbl (51): Population, total, Population growth (annual %), Surface area (sq....
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Let’s get a better handle on this data. We can use the function glimpse() to get a “glimpse” at our data.
glimpse(factbook_2015)
Rows: 217
Columns: 53
$ `Country Name` <chr> …
$ `Country Code` <chr> …
$ `Population, total` <dbl> …
$ `Population growth (annual %)` <dbl> …
$ `Surface area (sq. km)` <dbl> …
$ `Poverty headcount ratio at national poverty lines (% of population)` <dbl> …
$ `GNI, Atlas method (current US$)` <dbl> …
$ `GNI per capita, Atlas method (current US$)` <dbl> …
$ `GNI, PPP (current international $)` <dbl> …
$ `GNI per capita, PPP (current international $)` <dbl> …
$ `Income share held by lowest 20%` <dbl> …
$ `Life expectancy at birth, total (years)` <dbl> …
$ `Fertility rate, total (births per woman)` <dbl> …
$ `Adolescent fertility rate (births per 1,000 women ages 15-19)` <dbl> …
$ `Contraceptive prevalence, any method (% of married women ages 15-49)` <dbl> …
$ `Births attended by skilled health staff (% of total)` <dbl> …
$ `Mortality rate, under-5 (per 1,000 live births)` <dbl> …
$ `Prevalence of underweight, weight for age (% of children under 5)` <dbl> …
$ `Immunization, measles (% of children ages 12-23 months)` <dbl> …
$ `Primary completion rate, total (% of relevant age group)` <dbl> …
$ `School enrollment, secondary (% gross)` <dbl> …
$ `School enrollment, primary and secondary (gross), gender parity index (GPI)` <dbl> …
$ `Prevalence of HIV, total (% of population ages 15-49)` <dbl> …
$ `Forest area (sq. km)` <dbl> …
$ `Water productivity, total (constant 2015 US$ GDP per cubic meter of total freshwater withdrawal)` <dbl> …
$ `Energy use (kg of oil equivalent per capita)` <dbl> …
$ `CO2 emissions (metric tons per capita)` <dbl> …
$ `Electric power consumption (kWh per capita)` <dbl> …
$ `GDP (current US$)` <dbl> …
$ `GDP growth (annual %)` <dbl> …
$ `Inflation, GDP deflator (annual %)` <dbl> …
$ `Agriculture, forestry, and fishing, value added (% of GDP)` <dbl> …
$ `Industry (including construction), value added (% of GDP)` <dbl> …
$ `Exports of goods and services (% of GDP)` <dbl> …
$ `Imports of goods and services (% of GDP)` <dbl> …
$ `Gross capital formation (% of GDP)` <dbl> …
$ `Revenue, excluding grants (% of GDP)` <dbl> …
$ `Start-up procedures to register a business (number)` <dbl> …
$ `Market capitalization of listed domestic companies (% of GDP)` <dbl> …
$ `Military expenditure (% of GDP)` <dbl> …
$ `Mobile cellular subscriptions (per 100 people)` <dbl> …
$ `High-technology exports (% of manufactured exports)` <dbl> …
$ `Merchandise trade (% of GDP)` <dbl> …
$ `Net barter terms of trade index (2015 = 100)` <dbl> …
$ `External debt stocks, total (DOD, current US$)` <dbl> …
$ `Total debt service (% of GNI)` <dbl> …
$ `Net migration` <dbl> …
$ `Personal remittances, paid (current US$)` <dbl> …
$ `Foreign direct investment, net inflows (BoP, current US$)` <dbl> …
$ `Net ODA received per capita (current US$)` <dbl> …
$ `GDP per capita (current US$)` <dbl> …
$ `Foreign direct investment, net (BoP, current US$)` <dbl> …
$ `Inflation, consumer prices (annual %)` <dbl> …
We see that Country Name and Country Code are character columns while the others are numeric (i.e., dbl).
We can look at this data another way, using the function head() to look at the first six rows, and every column.
head(factbook_2015)
# A tibble: 6 × 53
`Country Name` `Country Code` `Population, total` Population growth (annual …¹
<chr> <chr> <dbl> <dbl>
1 Afghanistan AFG 33753499 3.12
2 Albania ALB 2880703 -0.291
3 Algeria DZA 39543154 2.00
4 American Samoa ASM 51368 -1.64
5 Andorra AND 71746 0.174
6 Angola AGO 28127721 3.62
# ℹ abbreviated name: ¹`Population growth (annual %)`
# ℹ 49 more variables: `Surface area (sq. km)` <dbl>,
# `Poverty headcount ratio at national poverty lines (% of population)` <dbl>,
# `GNI, Atlas method (current US$)` <dbl>,
# `GNI per capita, Atlas method (current US$)` <dbl>,
# `GNI, PPP (current international $)` <dbl>,
# `GNI per capita, PPP (current international $)` <dbl>, …
1.2.1 Cleaning column names
It looks like we have some column names that don’t use standard R practices (i.e., they have spaces, start with numbers). This isn’t a critical problem (meaning you can use column names like this - we know that because we have them here!) but it does make things slightly more difficult. The main difficulty is that you will have to refer to column names surrounded in back ticks and this can be annoying.
factbook_2015$`Country Name`
Let’s use the function clean_names() from the janitor package to clean those names up.
First, install the package janitor if you don’t have it.
install.packages("janitor")
Then we can load the package and clean up our column names.
library(janitor)
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
# old column namescolnames(factbook_2015)
[1] "Country Name"
[2] "Country Code"
[3] "Population, total"
[4] "Population growth (annual %)"
[5] "Surface area (sq. km)"
[6] "Poverty headcount ratio at national poverty lines (% of population)"
[7] "GNI, Atlas method (current US$)"
[8] "GNI per capita, Atlas method (current US$)"
[9] "GNI, PPP (current international $)"
[10] "GNI per capita, PPP (current international $)"
[11] "Income share held by lowest 20%"
[12] "Life expectancy at birth, total (years)"
[13] "Fertility rate, total (births per woman)"
[14] "Adolescent fertility rate (births per 1,000 women ages 15-19)"
[15] "Contraceptive prevalence, any method (% of married women ages 15-49)"
[16] "Births attended by skilled health staff (% of total)"
[17] "Mortality rate, under-5 (per 1,000 live births)"
[18] "Prevalence of underweight, weight for age (% of children under 5)"
[19] "Immunization, measles (% of children ages 12-23 months)"
[20] "Primary completion rate, total (% of relevant age group)"
[21] "School enrollment, secondary (% gross)"
[22] "School enrollment, primary and secondary (gross), gender parity index (GPI)"
[23] "Prevalence of HIV, total (% of population ages 15-49)"
[24] "Forest area (sq. km)"
[25] "Water productivity, total (constant 2015 US$ GDP per cubic meter of total freshwater withdrawal)"
[26] "Energy use (kg of oil equivalent per capita)"
[27] "CO2 emissions (metric tons per capita)"
[28] "Electric power consumption (kWh per capita)"
[29] "GDP (current US$)"
[30] "GDP growth (annual %)"
[31] "Inflation, GDP deflator (annual %)"
[32] "Agriculture, forestry, and fishing, value added (% of GDP)"
[33] "Industry (including construction), value added (% of GDP)"
[34] "Exports of goods and services (% of GDP)"
[35] "Imports of goods and services (% of GDP)"
[36] "Gross capital formation (% of GDP)"
[37] "Revenue, excluding grants (% of GDP)"
[38] "Start-up procedures to register a business (number)"
[39] "Market capitalization of listed domestic companies (% of GDP)"
[40] "Military expenditure (% of GDP)"
[41] "Mobile cellular subscriptions (per 100 people)"
[42] "High-technology exports (% of manufactured exports)"
[43] "Merchandise trade (% of GDP)"
[44] "Net barter terms of trade index (2015 = 100)"
[45] "External debt stocks, total (DOD, current US$)"
[46] "Total debt service (% of GNI)"
[47] "Net migration"
[48] "Personal remittances, paid (current US$)"
[49] "Foreign direct investment, net inflows (BoP, current US$)"
[50] "Net ODA received per capita (current US$)"
[51] "GDP per capita (current US$)"
[52] "Foreign direct investment, net (BoP, current US$)"
[53] "Inflation, consumer prices (annual %)"
# use clean_names and save over the current df factbook_2015factbook_2015 <-clean_names(factbook_2015)# new column namescolnames(factbook_2015)
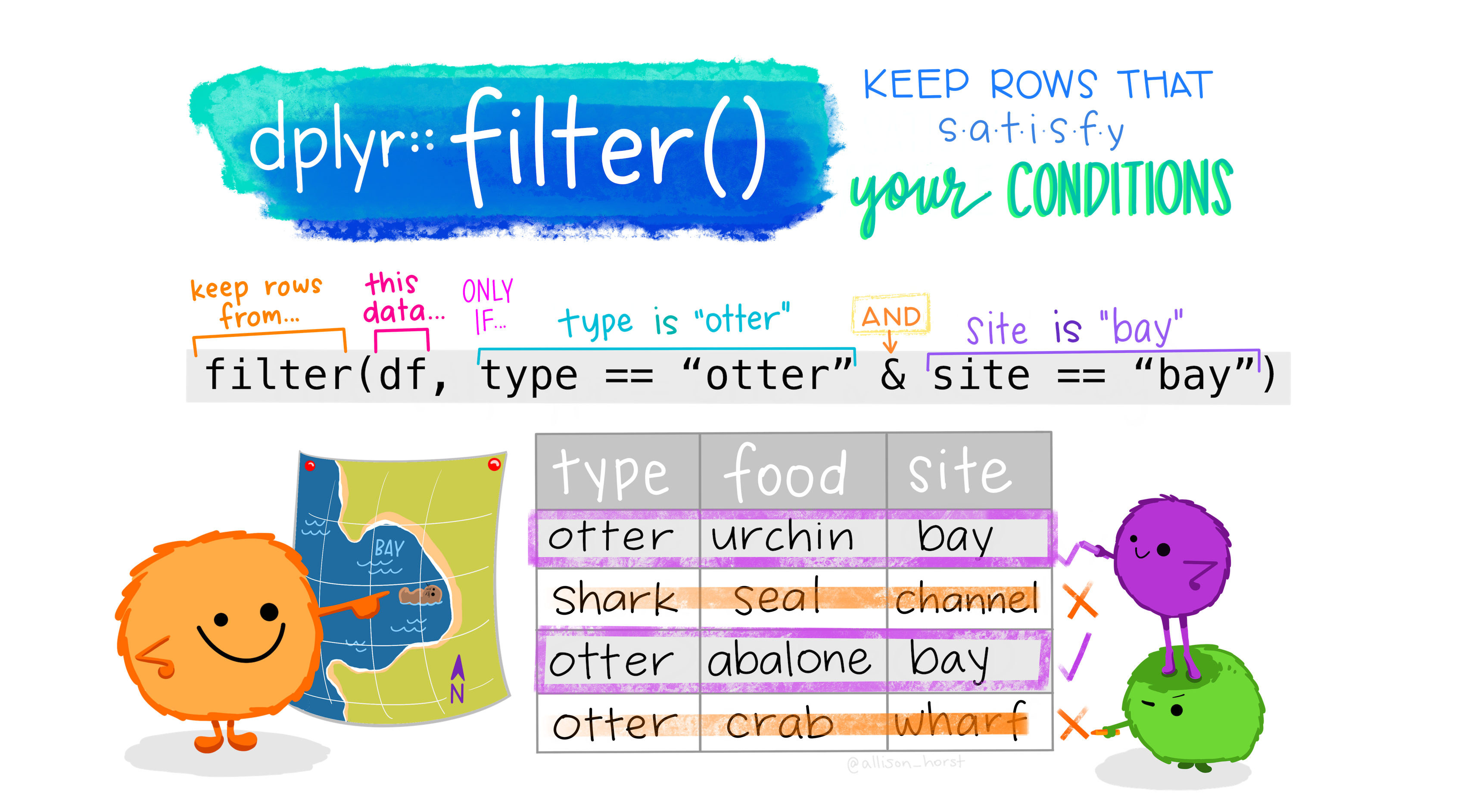
If we want to see the countries that also have an area that is less than the size of Ohio (116,098 km^2), we can also add that to our filter statement using the & operator.
In general I would recommend against this because its really hard to remember which column indices are which variables today, nevermind returning back to old code 1 year from now.
We can also select columns that are consecutive, using the : operator. Below I’m selecting the columns country_name through population_growth_annual_percent.
where(): selects columns where the statement given in the argument is TRUE
all_of(): matches all of the variable names in a character vector
any_of(): matches any of the names in a character vector
For example, we might want each column that has anything to do with gross domestic product, or gdp. We can select all of the columns which contain the string “gdp” in their name. I’m also going to add country_name so we know what we’re working with.
We can also select all column that meet a certain predicate. For example, we can pick all of the column that are of the type character.
factbook_2015 |>select(where(is.character))
# A tibble: 217 × 2
country_name country_code
<chr> <chr>
1 Afghanistan AFG
2 Albania ALB
3 Algeria DZA
4 American Samoa ASM
5 Andorra AND
6 Angola AGO
7 Antigua and Barbuda ATG
8 Argentina ARG
9 Armenia ARM
10 Aruba ABW
# ℹ 207 more rows
We can also combine selections using the & (and), | (or), and ! (not) operators. For example, if I want the columns about GNI but only the international ones I can:
# A tibble: 217 × 2
gni_ppp_current_international gni_per_capita_ppp_current_international
<dbl> <dbl>
1 77739869000 2300
2 33981401261 11800
3 541234000000 13690
4 NA NA
5 NA NA
6 190283000000 6760
7 1766297473 19640
8 848960000000 19680
9 30505448341 10600
10 3718236361 35660
# ℹ 207 more rows
We can also use select() to order our columns, as the order we select them in dictates the order they will exist in our dataframe.
3.1 Practice
Come up with 3 different ways to select the columns about children, and make sure you also include a country column so you know what you’re looking at.
Need a hint?
Here are the columns that I’m considering to be about children:
# A tibble: 217 × 7
country_name mortality_rate_under_5_per_1_000…¹ prevalence_of_underw…²
<chr> <dbl> <dbl>
1 Afghanistan 72.7 NA
2 Albania 9.6 NA
3 Algeria 25.3 NA
4 American Samoa NA NA
5 Andorra 3.6 NA
6 Angola 87.9 19
7 Antigua and Barbuda 10.9 NA
8 Argentina 11.8 NA
9 Armenia 14.5 NA
10 Aruba NA NA
# ℹ 207 more rows
# ℹ abbreviated names: ¹mortality_rate_under_5_per_1_000_live_births,
# ²prevalence_of_underweight_weight_for_age_percent_of_children_under_5
# ℹ 4 more variables:
# immunization_measles_percent_of_children_ages_12_23_months <dbl>,
# primary_completion_rate_total_percent_of_relevant_age_group <dbl>,
# school_enrollment_secondary_percent_gross <dbl>, …
By index:
factbook_2015 |>select(1, 17:22)
# A tibble: 217 × 7
country_name mortality_rate_under_5_per_1_000…¹ prevalence_of_underw…²
<chr> <dbl> <dbl>
1 Afghanistan 72.7 NA
2 Albania 9.6 NA
3 Algeria 25.3 NA
4 American Samoa NA NA
5 Andorra 3.6 NA
6 Angola 87.9 19
7 Antigua and Barbuda 10.9 NA
8 Argentina 11.8 NA
9 Armenia 14.5 NA
10 Aruba NA NA
# ℹ 207 more rows
# ℹ abbreviated names: ¹mortality_rate_under_5_per_1_000_live_births,
# ²prevalence_of_underweight_weight_for_age_percent_of_children_under_5
# ℹ 4 more variables:
# immunization_measles_percent_of_children_ages_12_23_months <dbl>,
# primary_completion_rate_total_percent_of_relevant_age_group <dbl>,
# school_enrollment_secondary_percent_gross <dbl>, …
# A tibble: 217 × 7
country_name mortality_rate_under_5_per_1_000…¹ prevalence_of_underw…²
<chr> <dbl> <dbl>
1 Afghanistan 72.7 NA
2 Albania 9.6 NA
3 Algeria 25.3 NA
4 American Samoa NA NA
5 Andorra 3.6 NA
6 Angola 87.9 19
7 Antigua and Barbuda 10.9 NA
8 Argentina 11.8 NA
9 Armenia 14.5 NA
10 Aruba NA NA
# ℹ 207 more rows
# ℹ abbreviated names: ¹mortality_rate_under_5_per_1_000_live_births,
# ²prevalence_of_underweight_weight_for_age_percent_of_children_under_5
# ℹ 4 more variables:
# immunization_measles_percent_of_children_ages_12_23_months <dbl>,
# primary_completion_rate_total_percent_of_relevant_age_group <dbl>,
# school_enrollment_primary_and_secondary_gross_gender_parity_index_gpi <dbl>, …
These are just some ways!
4 Sorting data with arrange()
A nice helper function for looking at your data is arrange() which sorts your data.
We can sort our data based on how much forest (forest_area_sq_km) each country has.
# A tibble: 217 × 3
country_name surface_area_sq_km forest_area_sq_km
<chr> <dbl> <dbl>
1 Russian Federation 17098250 8149305.
2 Brazil 8515770 5038848
3 Canada 9879750 3471157.
4 United States 9831510 3100950
5 China 9562911 2102942.
6 Australia 7741220 1330945
7 Congo, Dem. Rep. 2344860 1316621.
8 Indonesia 1913580 950279
9 Peru 1285220 731945.
10 India 3287260 708280
# ℹ 207 more rows
Wow almost 50% of Russia is forested.
4.1 Practice
Which countries have the lowest cell phone subscriptions? mobile_cellular_subscriptions_per_100_people
Need a hint?
You can use the function arrange() to sort your columns. The default arranging is from low to high, so if you want to go from high to low, you can set arrange(desc()).