Accessing and using R at the Ohio Supercomputer Center (OSC)
![]()
1 Today’s content
Today, I will show you how to access resources such as R and RStudio through the Ohio Supercomputer Center (OSC). To give some context, I will start with a brief general introduction to high-performance computing and OSC.
Since this is the last Code CLub session of the semester, we will also leave for more general questions and comments and ask for suggestions for content for the next semester of Code Club.
2 High-performance computing and OSC
A supercomputer (also known as a “compute cluster” or simply a “cluster”) consists of many computers that are connected by a high-speed network, and that can be accessed remotely by its users. In more general terms, supercomputers provide high-performance computing (HPC) resources.
This is what Owens, one of the OSC supercomputers, physically looks like:

Here are some possible reasons to use a supercomputer instead of your own laptop or desktop:
- Your analyses take a long time to run, need large numbers of CPUs, or a large amount of memory.
- You need to run some analyses many times.
- You need to store a lot of data.
- Your analyses require specialized hardware, such as GPUs (Graphical Processing Units).
- Your analyses require software available only for the Linux operating system, but you use Windows.
The Ohio Supercomputer Center (OSC) is a facility provided by the state of Ohio. It has three supercomputers, lots of storage space, and an excellent infrastructure for accessing these resources.
OSC has three main websites — we will mostly or only use the first:
- https://ondemand.osc.edu: A web portal to use OSC resources through your browser (login needed).
- https://my.osc.edu: Account and project management (login needed).
- https://osc.edu: General website with information about the supercomputers, installed software, and usage.
Access to OSC’s computing power and storage space goes through OSC “Projects”:
- A project can be tied to a research project or lab, or be educational like Code Club’s project,
PAS1838. - Each project has a budget in terms of “compute hours” and storage space1.
- As a user, it’s possible to be a member of multiple different projects.
3 The structure of a supercomputer center
Terminology
Let’s start with some (super)computing terminology, going from smaller things to bigger things:
- Node
A single computer that is a part of a supercomputer. - Supercomputer / Cluster
A collection of computers connected by a high-speed network. OSC currently has three: “Pitzer”, “Owens”, and “Cardinal”. - Supercomputer Center
A facility like OSC that has one or more supercomputers.
Supercomputer components
We can think of a supercomputer as having three main parts:
- File Systems: Where files are stored (these are shared between the two OSC supercomputers!)
- Login Nodes: The handful of computers everyone shares after logging in
- Compute Nodes: The many computers you can reserve to run your analyses
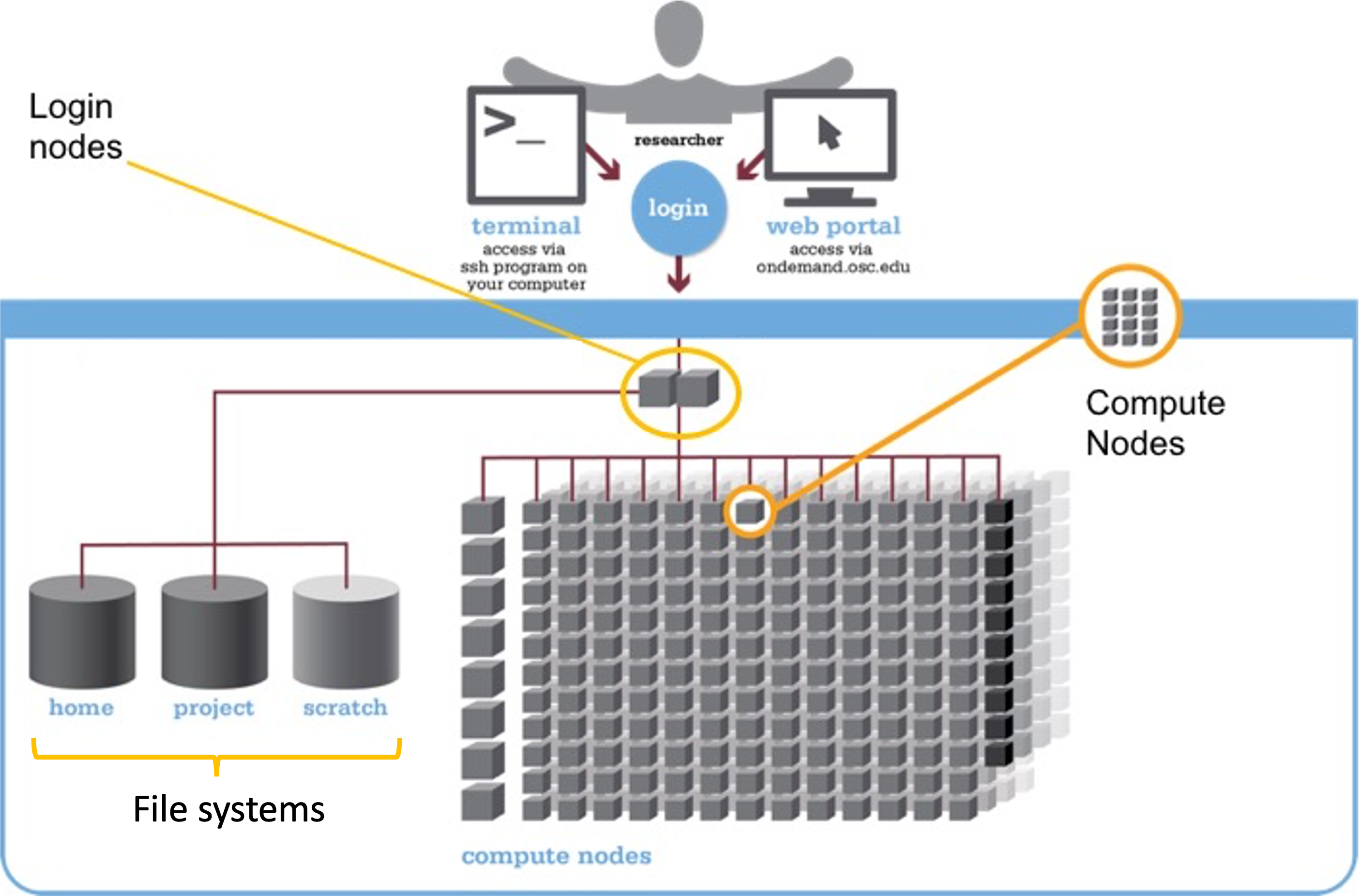
Login Nodes
Login nodes are set aside as an initial landing spot for everyone who logs in to a supercomputer. There are only a handful of them on each supercomputer, they are shared among everyone, and cannot be “reserved”.
As such, login nodes are meant only to do things like organizing your files and creating scripts for compute jobs, and are not meant for any serious computing, which should be done on the compute nodes.
Compute Nodes
Data processing and analysis is done on compute nodes. You can only use compute nodes after putting in a request for resources (a “job”). The Slurm job scheduler, which we will learn to use in week 5, will then assign resources to your request.
Compared to command-line computing on a laptop or desktop, a number of aspects are different when working on a supercomputer like at OSC. We’ll learn much more about these later on in the course, but here is an overview:
- “Non-interactive” computing is common
It is common to write and “submit” scripts to a queue instead of running programs interactively. - Software
You generally can’t install “the regular way”, and a lot of installed software needs to be “loaded”. - Operating system
Supercomputers run on the Linux operating system. - Login versus compute nodes
As mentioned, the nodes you end up on after logging in are not meant for heavy computing and you have to request access to “compute nodes” to run most analyses.
OSC has several distinct file systems:
| File system | Located within | Quota | Backed up? | Auto-purged? | One for each… |
|---|---|---|---|---|---|
| Home | /users/ |
500 GB / 1 M files | Yes | No | User |
| Project | /fs/ess/ |
Flexible | Yes | No | OSC Project |
| Scratch | /fs/scratch/ |
100 TB | No | After 90 days | OSC Project |
(Directory is just another word for folder, often written as “dir” for short.)
4 OSC OnDemand
The OSC OnDemand web portal allows you to use a web browser to access OSC resources such as:
- A file browser where you can also create and rename folders and files, etc.
- A Unix shell
- “Interactive Apps”: programs such as RStudio, Jupyter, VS Code and QGIS.
Go to https://ondemand.osc.edu and log in (use the boxes on the left-hand side)
You should see a landing page similar to the one below:
We will now go through some of the dropdown menus in the blue bar along the top.
Files: File system access
Hovering over the Files dropdown menu gives a list of directories that you have access to. If your account is brand new, and you were added to PAS1838, you should only have three directories listed:
- A Home directory (starts with
/users/) - The
PAS1838project’s “scratch” directory for temporary project-related storage (/fs/scratch/PAS1838) - The
PAS1838project’s “project” directory for permanent project-related storage (/fs/ess/PAS1838)
You will only ever have one Home directory at OSC, but for every additional project you are a member of, you should usually see additional /fs/ess and /fs/scratch directories appear.
Click on your Home directory.
Once there, you should see whichever directories and files are present at the selected location, and you can click on the directories to explore the contents further:
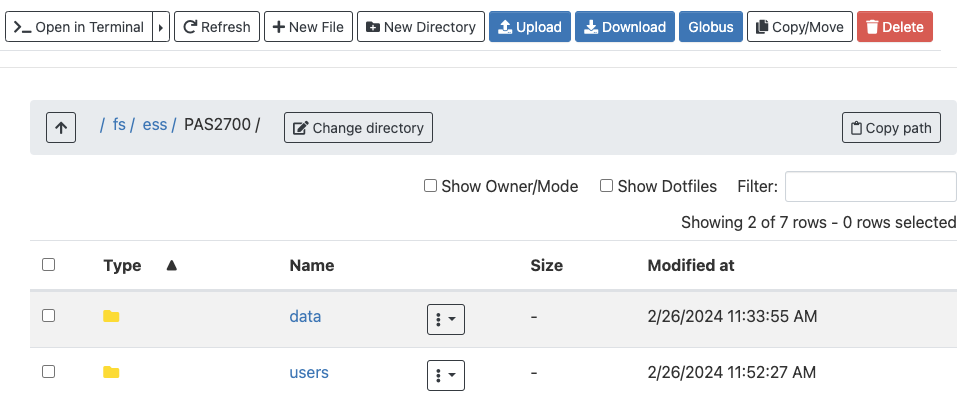
This interface is much like the file browser on your own computer, so you can also create, delete, move and copy files and folders, and even upload (from your computer to OSC) and download (from OSC your computer) files2 — see the buttons across the top.
Clusters: Unix shell access
Interacting with a supercomputer is most commonly done using a Unix shell. Under the Clusters dropdown menu, you can access a Unix shell either on Owens or Pitzer:
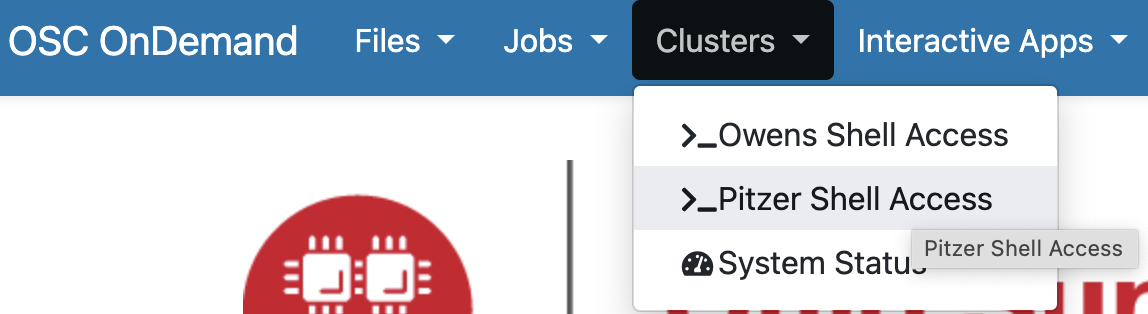
I’m selecting a shell on the Pitzer supercomputer (“Pitzer Shell Access”), which will open a new browser tab, where the bottom of the page looks like this:
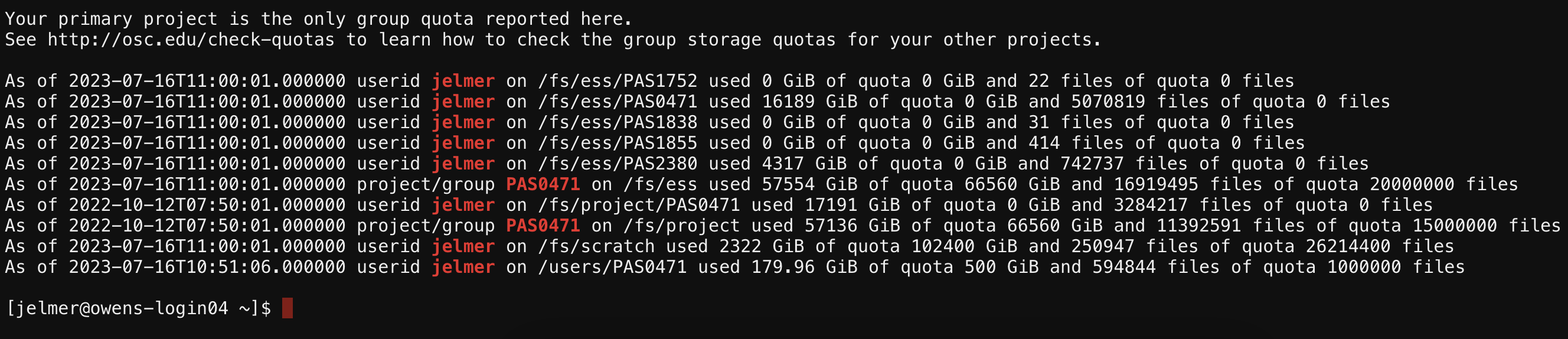
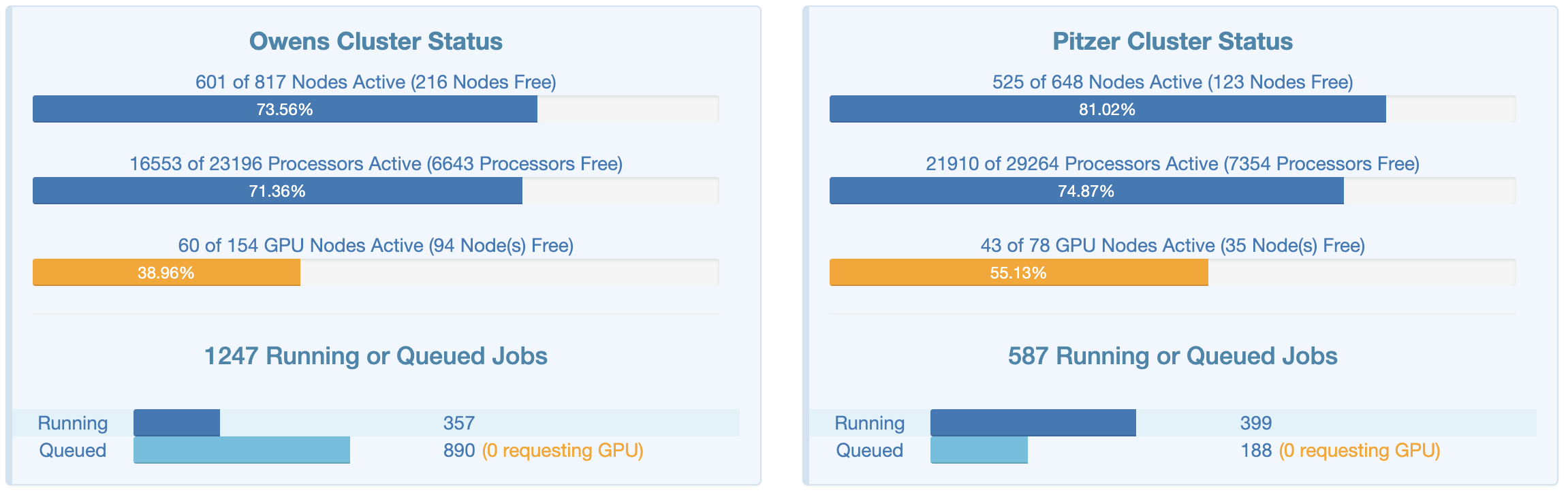
The “Clusters” dropdown menu also has item “System Status”. When you click on that, a new browser tab will open with a page that shows an overview of the live, current usage of the clusters — this can be useful to get an idea of the scale of the supercomputer center, which cluster is being used more, and so on:
Interactive Apps
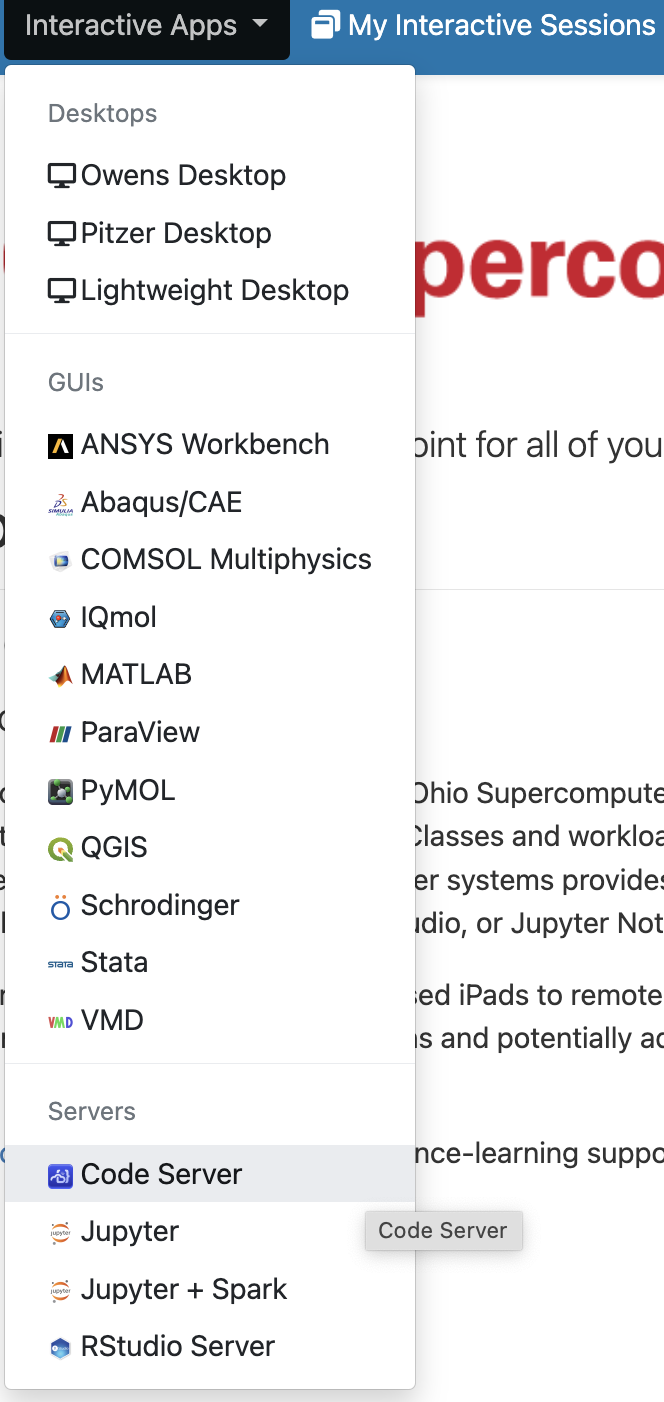
We can access programs with Graphical User Interfaces (GUIs; point-and-click interfaces) via the Interactive Apps dropdown menu:
5 RStudio at OSC (RStudio Server)
From within our browser, we can access a version of RStudio (“RStudio Sever”) that will be running on OSC’s computers.
Some potential advantages of doing this are:
- You can access multiple different versions of R!
- You have access to OSC’s compute power and could easily request say 20 cores or 100 GB of memory (RAM)
- You have large amounts of data that are stored on OSC anyway, or are best stored there
Starting an RStudio Server session
Click on
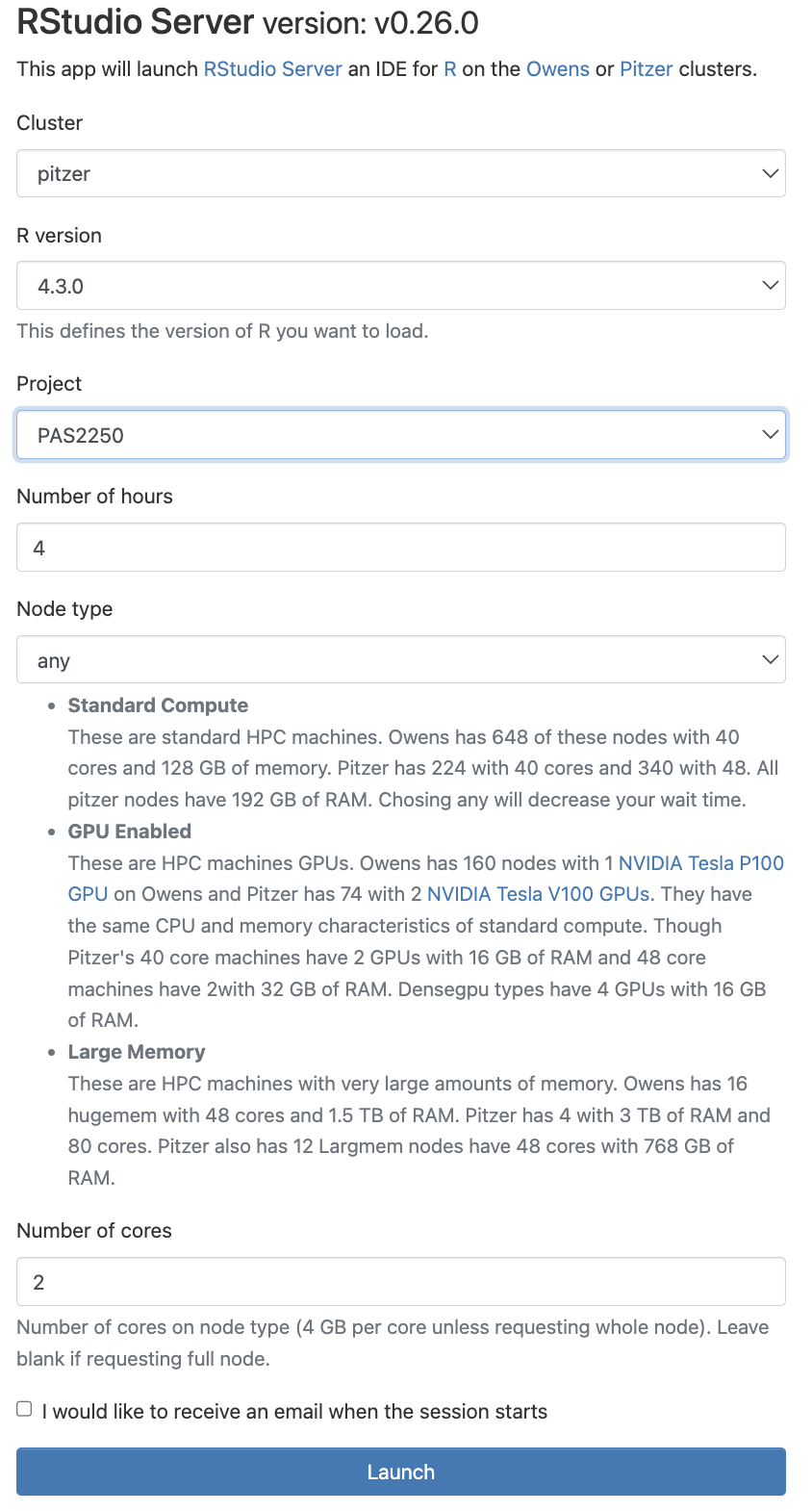
Interactive Apps(top bar) and thenRStudio Server(all the way at the bottom)Fill out the form as follows:
- Cluster:
Pitzer - R version:
4.4.0 - Project:
PAS1838 - Number of hours:
1 - Node type:
any - Number of cores:
1
- Cluster:
Click to see a screenshot
Click the big blue
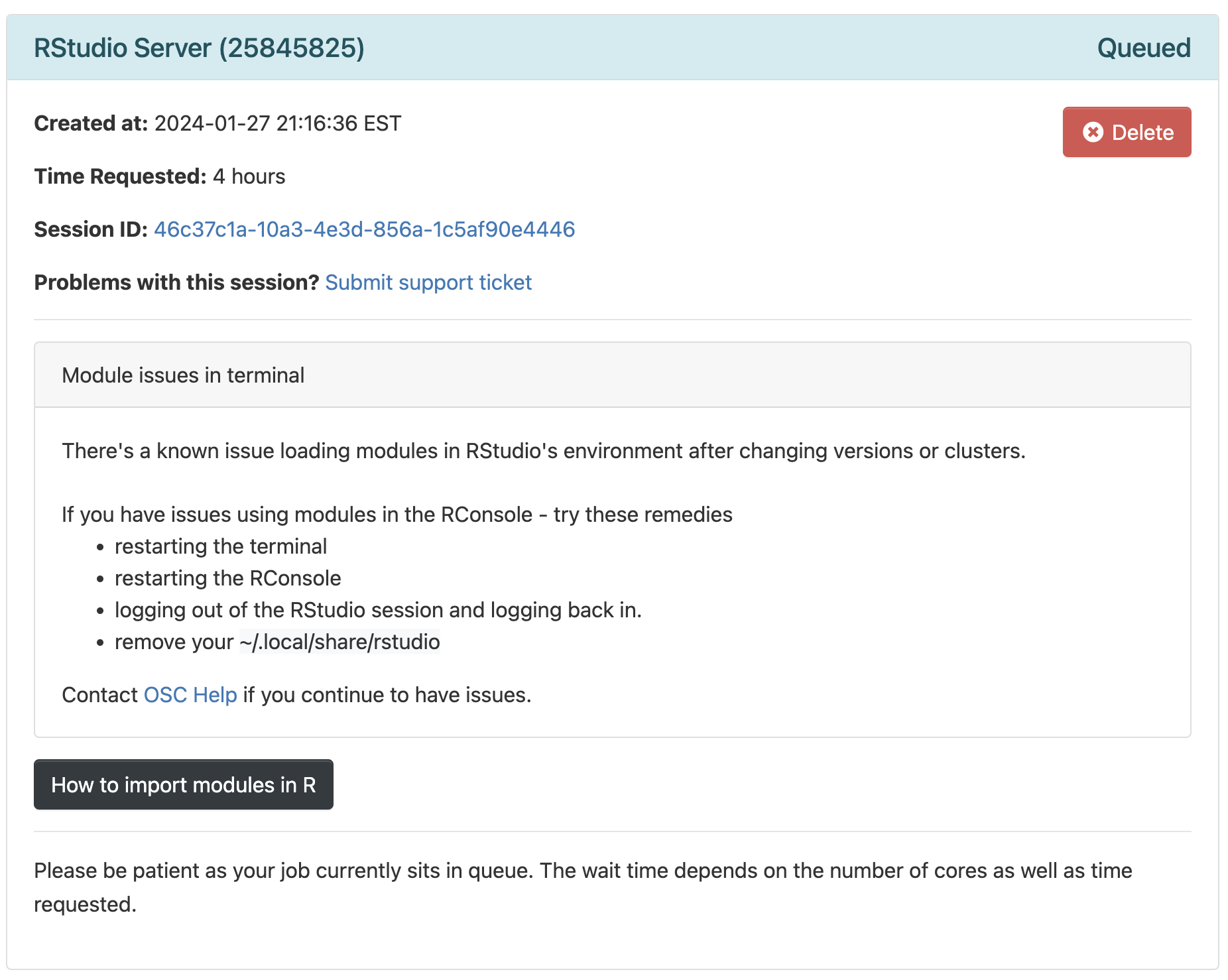
Launchbutton at the bottomNow, you should be sent to a new page with a box at the top for your RStudio Server “job”, which should initially be “Queued” (waiting to start).
Click to see a screenshot
- Your job should start running very soon, with the top bar of the box turning green and saying “Running”.
Click to see a screenshot
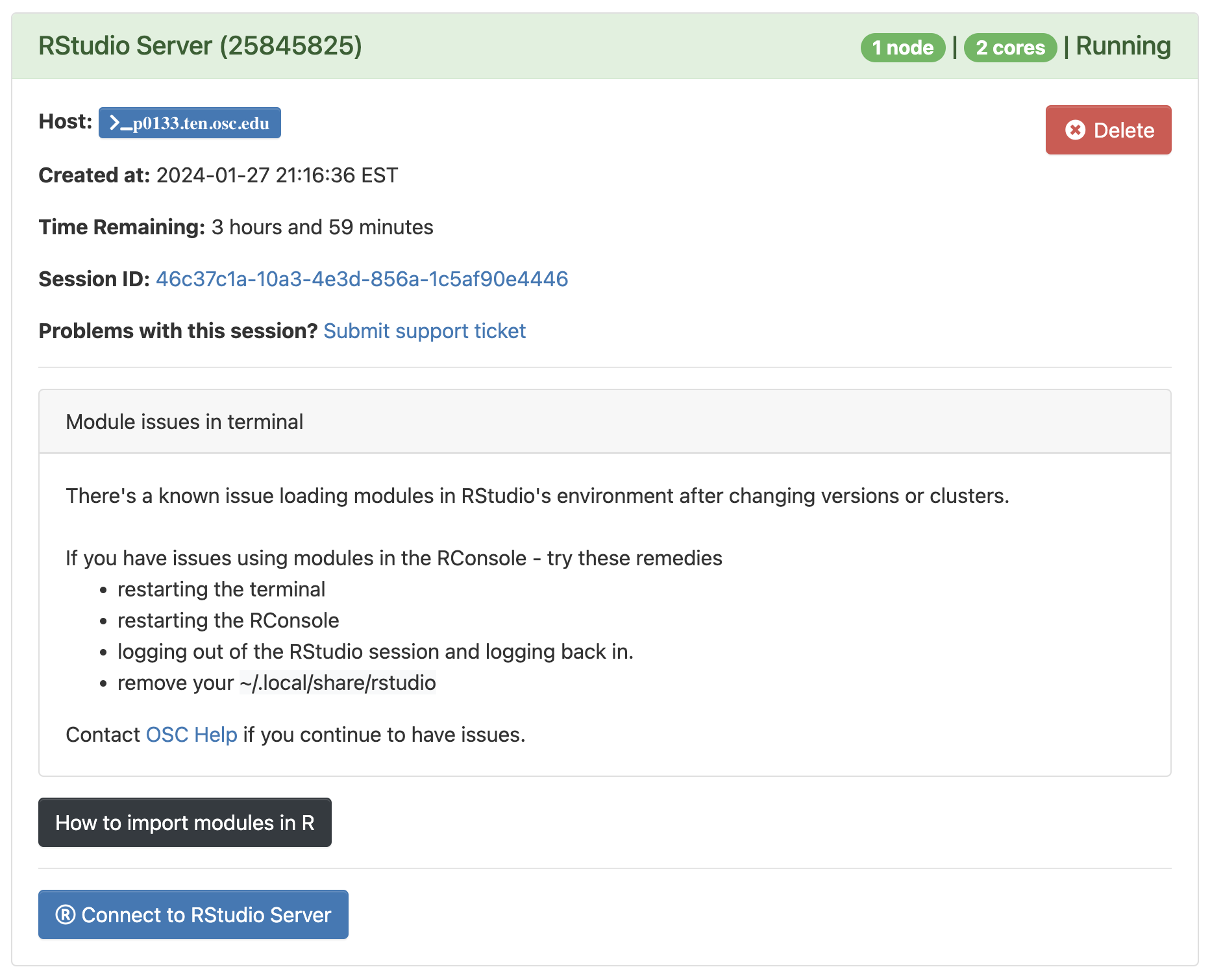
- Click
Connect to RStudio Serverat the bottom of the box, and an RStudio Server instance will open in a new browser tab. You’re ready to go!
Installing R packages
You can install R packages as usual with install.packages() and related functions: these will automatically be installed in your default personal library somewhere in your Home directory.